5 Powerful Techniques to Slash Your LLM Costs by Up to 90%
Building AI applications doesn’t have to break the bank. We have 5 tips to help you cut your LLM costs by up to 90% while maintaining top-notch performance—because we also hate hidden expenses.

Building AI Apps Isn’t as Easy (or Cheap) as You Think
Creating an AI app might seem straightforward—with powerful models like GPT-4 at your fingertips, you’re ready to take the world by storm. But as many developers and startups quickly discover, the reality isn’t so simple. While building an AI app isn’t necessarily hard, costs can quickly add up, especially with models like GPT-4 Turbo charging 1 to 3 cents per 1,000 input/output tokens.
The Hidden Cost of AI Workflows
Sure, you could opt for cheaper models like GPT-3.5 or open-source alternatives like Llama or Mistral, throw everything into one API call with excellent prompt engineering, and hope for the best. However, this approach often falls short in production environments.
The non-deterministic nature of LLMs means that even a 99% accuracy rate isn’t enough; that 1% failure can break a user’s experience. Imagine a major software company operating at this level of reliability—it’s simply unacceptable. AI applications today are often unreliable, and this unreliability can be costly.

Whether you’re wrestling with bloated API bills or struggling to balance performance with affordability, there are effective strategies to tackle these challenges. Here’s how you can keep your AI app costs in check without sacrificing performance.
1. Optimize Your Prompts
Optimizing your prompts is one of the simplest yet most effective ways to reduce LLM costs. Since you’re charged based on the number of tokens processed, crafting concise and specific prompts can significantly lower your expenses.
For example, your original prompt might look something like this:
Please write an outline for a blog post on climate change. It should cover the causes, effects, and possible solutions to climate change, and it should be structured in a way that is engaging and easy to read.
Instead, you can optimize it to:
Create an engaging blog post outline on climate change, including causes, effects, and solutions.
This shorter prompt conveys the same information while using fewer tokens, directly translating to cost savings.
2. Implement response caching
Response caching is a powerful technique that involves storing and reusing previously generated responses. By caching responses, you can avoid redundant requests to the LLM, saving both processing time and costs. This is particularly beneficial for applications with repetitive or predictable user interactions, such as chatbots and customer support systems.
With Helicone, you can reduce latency and save costs on LLM API calls by caching responses. You get further customization such as configuring cache duration, bucket sizes, and using cache seeds for consistent results across requests.
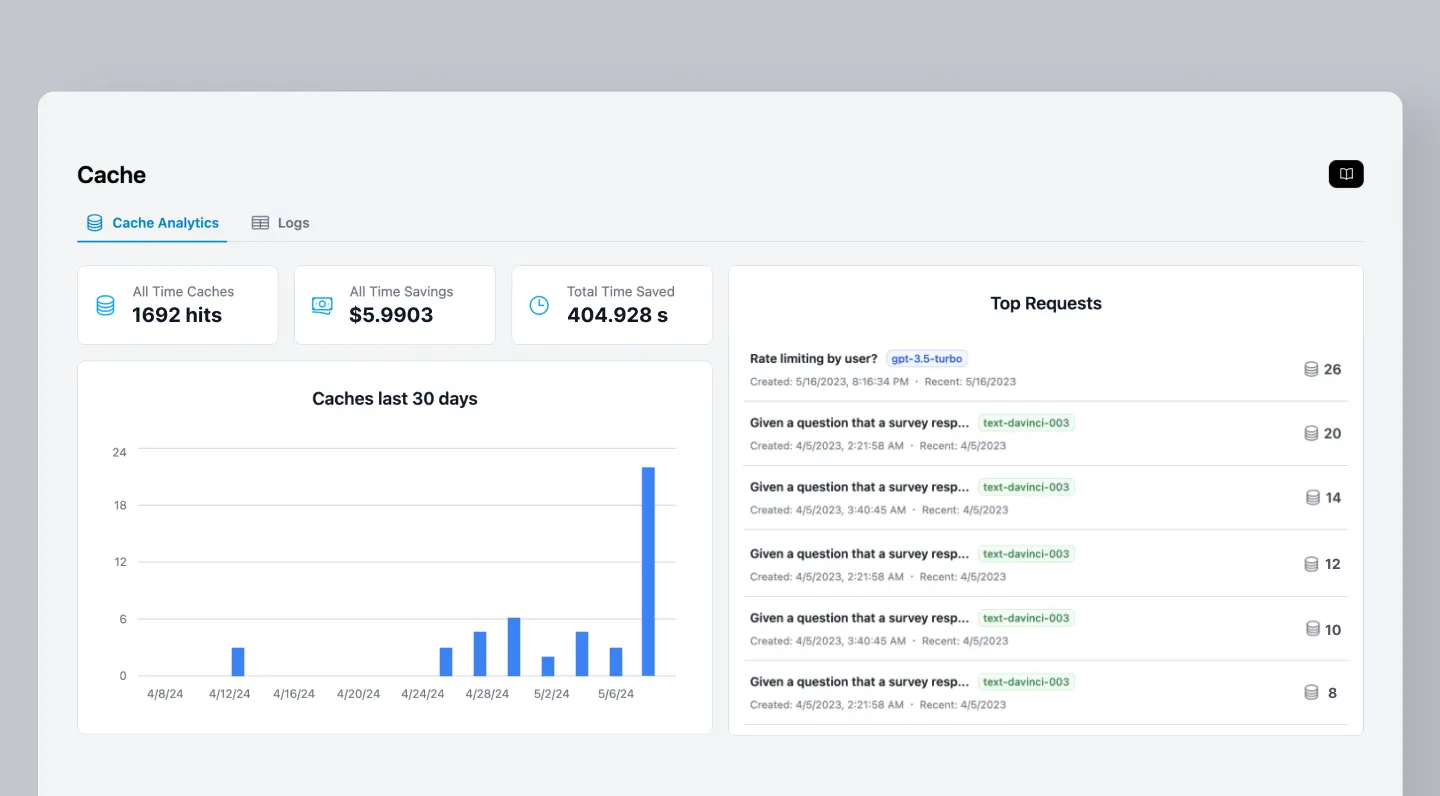
Want to know more about how it works? Check out Helicone’s docs.
3. Use Task-Specific, Smaller Models
While it’s tempting to use the largest and most powerful LLMs for every task, this approach can be unnecessarily expensive. Instead, consider using smaller, task-specific models that are fine-tuned for your particular use case. These specialized models often deliver better results than their larger, more general counterparts when it comes to specific tasks.
Fine-Tuning Open-Source Models
You can also fine-tune your LLM to reduce costs. Fine-tuning involves training the model on a smaller, task-specific dataset, which helps it learn patterns relevant to your application.
For example, if you’re using an LLM for customer support, you can fine-tune it on a dataset of customer inquiries and responses. This process makes the model more effective at handling common queries, potentially reducing the number of tokens needed per request and lowering overall costs.
Many LLM providers, such as OpenAI and Hugging Face, offer tools and resources for fine-tuning their models. You can also use tools like OpenPipe that simplify fine-tuning open-source models. By replacing the OpenAI SDK with OpenPipe’s, you can fine-tune a cheaper model like Mistral 7B, resulting in up to an 85% cost reduction.
Case Study: Cutting LLM Costs by 83% with Monitoring Tools
Companies like Dataherald have successfully reduced their LLM costs by using monitoring tools. By implementing platforms like Helicone or LangSmith, they were able to identify inefficiencies in their applications, such as uncontrolled token usage in specific components, and make adjustments that led to significant cost savings.
For instance, they discovered that their few-shot sample retriever’s token usage was growing uncontrollably, consuming up to 150,000 tokens per query. By addressing this issue, they managed to reduce token usage by 83%, dramatically lowering their operational costs.
Q: How can I determine which model is the most cost-effective for my AI application?
A: Start by defining the specific tasks and requirements your application needs to handle. Test different models by comparing their performance, cost per token, and how well they handle your specific use cases. Look for a model that offers the best balance between cost and performance, and consider fine-tuning cheaper models if needed.
4. Use RAG instead of sending everything to the LLM
You can also use Retrieval-Augmented Generation (RAG) instead of sending all data directly to the LLM. RAG combines information retrieval with language generation by first searching a pre-indexed database to find relevant snippets, which are then provided to the LLM along with the original query.
This approach reduces the amount of data sent to the LLM, cutting down on API calls and processing tokens, which lowers costs. RAG can improve response quality by incorporating up-to-date and contextually relevant information not included in the LLM’s training data.
Implementing RAG does require some setup and maintenance, but its benefits in cost reduction and response accuracy can make it valuable for your application.
5. Incorporate Observability and Monitoring
Having a deep understanding of the cost patterns in your LLM application is crucial for effective cost optimization. By using observability platforms like Helicone, you can monitor the cost for each large language model, compare model outputs and optimize your prompt.
Some alternatives like LangSmith from LangChain, have steeper learning curves, closed-source limitations, and rigid pricing structures. Others like Datadog, are more generalized and not specifically tailored for Large Language Models.
Helicone takes a simpler approach with a 1-line integration that works across various models and providers. By integrating these tools into your development and production workflows, you can make data-driven decisions to reduce your LLM costs significantly.
Q: How often should I monitor and optimize my LLM costs?
A: Regularly monitor and optimize your LLM costs, especially as your usage scales. Aim to review your costs monthly or quarterly, analyze usage patterns, and identify high-cost areas. Implement cost-saving measures such as fine-tuning models, optimizing prompt design, or switching to less expensive models when possible.

Conclusion
If you’re building an AI app, consider your architecture’s reliability and costs upfront. Start by reviewing your current models and consider where these strategies could make the biggest impact. Ask yourself:
- Is there a viable, cheaper model that can be fine-tuned to meet your needs?
- Are there components of your application that are consuming excessive tokens?
- Can monitoring tools help you identify and fix inefficiencies?
Remember, the key is to find the right balance between cost-efficiency and performance that works best for your specific use case. By implementing these techniques and utilizing observability platforms, you can reduce your LLM costs by up to 90% without compromising on quality.
Questions or feedback?
Are the information out of date? Please raise an issue and we’d love to share your tips!